

Hands-On NoSQL with MongoDB: From Theory to Practice
MongoDB is the most popular NoSQL database, but if you’re coming from a SQL background, it can feel like learning a completely different language. Today, we’re going hands-on to see exactly how document databases solve real data engineering problems.
Here’s a scenario we’ll use to see MongoDB in action: You’re a data engineer at a growing e-commerce company. Your customer review system started simple: star ratings and text reviews in a SQL database. But success has brought complexity. Marketing wants verified purchase badges. The mobile team is adding photo uploads. Product management is launching video reviews. Each change requires schema migrations that take hours with millions of existing reviews.
Sound familiar? This is the schema evolution problem that drives data engineers to NoSQL. Today, you’ll see exactly how MongoDB solves it. We’ll build this review system from scratch, handle those evolving requirements without a single migration, and connect everything to a real analytics pipeline.
Ready to see why MongoDB powers companies from startups to Forbes? Let’s get started.
Setting Up MongoDB Without the Complexity
We’re going to use MongoDB Atlas, their managed cloud service. We’re using Atlas because it mirrors how you’ll actually deploy MongoDB in most professional environments. Alternatively, you could install MongoDB locally if you prefer. We’ll use Atlas because it’s quick to set up and gets us straight to learning MongoDB concepts.
1. Create your account
Go to MongoDB’s Atlas page and create a free account. You won’t need to provide any credit card information — the free tier gives you 512MB of storage, which is more than enough for learning and even small production workloads. Once you’re signed up, you’ll create your first cluster.
Click “Build a Database” and select the free shared cluster option. Select any cloud provider and choose a region near you. The defaults are fine because we’re learning concepts, not optimizing performance. Name your cluster something simple, like “learning-cluster,” and click Create.
2. Set up the database user and network access
While MongoDB sets up your distributed database cluster (yes, even the free tier is distributed across multiple servers), you need to configure access. MongoDB requires two things: a database user and network access rules.
For the database user, click “Database Access” in the left menu and add a new user. Choose password authentication and create credentials you’ll remember. For permissions, select “Read and write to any database.” Note that in production you’d be more restrictive, but we’re learning.
For network access, MongoDB may have already configured this during signup through their quickstart flow. Check “Network Access” in the left menu to see your current settings. If nothing is configured yet, click “Add IP Address” and select “Allow Access from Anywhere” for now (in production, you’d restrict this to specific IP addresses for security).
Your cluster should be ready in about three minutes. When it’s done, click the “Connect” button on your cluster. You’ll see several connection options.
3. Connect to MongoDB Compass
Choose “MongoDB Compass.” This is MongoDB’s GUI tool that makes exploring data visual and intuitive.

Download Compass if you don’t have it, then copy your connection string. It looks like this:
mongodb+srv://myuser:<password>@learning-cluster.abc12.mongodb.net/Replace <password> with your actual password and connect through Compass. When it connects successfully, you’ll see your cluster with a few pre-populated databases like admin, local, and maybe sample_mflix (MongoDB’s movie database for demos). These are system databases and sample data (we’ll create our own database next).

You’ve just set up a distributed database system that can scale to millions of documents. The same setup process works whether you’re learning or launching a startup.
Understanding Documents Through Real Data
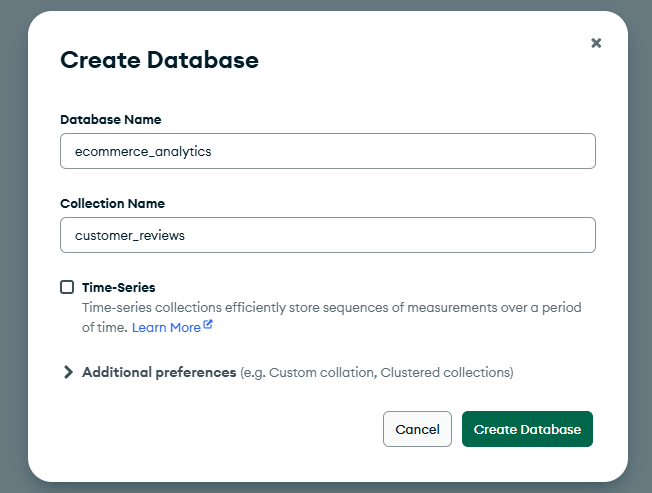
Now let’s build our review system. In MongoDB Compass, you’ll see a green “Create Database” button. Click it and create a database called ecommerce_analytics with a collection called customer_reviews.
A quick note on terminology: In MongoDB, a database contains collections, and collections contain documents. If you’re coming from SQL, think of collections like tables and documents like rows, except documents are much more flexible.
Click into your new collection. You could add data through the GUI by clicking “Add Data” → “Insert Document”, but let’s use the built-in shell instead to get comfortable with MongoDB’s query language. At the top right of Compass, look for the shell icon (“>_”) and click “Open MongoDB shell.”
First, make sure we’re using the right database:
use ecommerce_analyticsNow let’s insert our first customer review using insertOne:
db.customer_reviews.insertOne({
customer_id: "cust_12345",
product_id: "wireless_headphones_pro",
rating: 4,
review_text: "Great sound quality, battery lasts all day. Wish they were a bit more comfortable for long sessions.",
review_date: new Date("2024-10-15"),
helpful_votes: 23,
verified_purchase: true,
purchase_date: new Date("2024-10-01")
})MongoDB responds with confirmation that it worked:
{
acknowledged: true,
insertedId: ObjectId('68d31786d59c69a691408ede')
}This is a complete review stored as a single document. In a traditional SQL database, this information might be spread across multiple tables: a reviews table, a votes table, maybe a purchases table for verification. Here, all the related data lives together in one document.
Now here’s a scenario that usually breaks SQL schemas: the mobile team ships their photo feature, and instead of planning a migration, they just start storing photos:
db.customer_reviews.insertOne({
customer_id: "cust_67890",
product_id: "wireless_headphones_pro",
rating: 5,
review_text: "Perfect headphones! See the photo for size comparison.",
review_date: new Date("2024-10-20"),
helpful_votes: 45,
verified_purchase: true,
purchase_date: new Date("2024-10-10"),
photo_url: "https://cdn.example.com/reviews/img_2024_10_20_abc123.jpg",
device_type: "mobile_ios"
})See the difference? We added photo_url and device_type fields, and MongoDB didn’t complain about missing columns or require a migration. Each document just stores what makes sense for it. Of course, this flexibility comes with a trade-off: your application code needs to handle documents that might have different fields. When you’re processing reviews, you’ll need to check if a photo exists before trying to display it.
Let’s add a few more reviews to build a realistic dataset (notice we’re using insertMany here):
db.customer_reviews.insertMany([
{
customer_id: "cust_11111",
product_id: "laptop_stand_adjustable",
rating: 3,
review_text: "Does the job but feels flimsy",
review_date: new Date("2024-10-18"),
helpful_votes: 5,
verified_purchase: false
},
{
customer_id: "cust_22222",
product_id: "wireless_headphones_pro",
rating: 5,
review_text: "Excelente producto! La calidad de sonido es increíble.",
review_date: new Date("2024-10-22"),
helpful_votes: 12,
verified_purchase: true,
purchase_date: new Date("2024-10-15"),
video_url: "https://cdn.example.com/reviews/vid_2024_10_22_xyz789.mp4",
video_duration_seconds: 45,
language: "es"
},
{
customer_id: "cust_33333",
product_id: "laptop_stand_adjustable",
rating: 5,
review_text: "Much sturdier than expected. Height adjustment is smooth.",
review_date: new Date("2024-10-23"),
helpful_votes: 8,
verified_purchase: true,
sentiment_score: 0.92,
sentiment_label: "very_positive"
}
])Take a moment to look at what we just created. Each document tells its own story: one has video metadata, another has sentiment scores, one is in Spanish. In a SQL world, you’d be juggling nullable columns or multiple tables. Here, each review just contains whatever data makes sense for it.
Querying Documents
Now that we have data, let’s retrieve it. MongoDB’s query language uses JSON-like syntax that feels natural once you understand the pattern.
Find matches
Finding documents by exact matches is straightforward using the find method with field names as keys:
// Find all 5-star reviews
db.customer_reviews.find({ rating: 5 })
// Find reviews for a specific product
db.customer_reviews.find({ product_id: "wireless_headphones_pro" })You can use operators for more complex queries. MongoDB has operators like $gte (greater than or equal), $lt (less than), $ne (not equal), and many others:
// Find highly-rated reviews (4 stars or higher)
db.customer_reviews.find({ rating: { $gte: 4 } })
// Find recent verified purchase reviews
db.customer_reviews.find({
verified_purchase: true,
review_date: { $gte: new Date("2024-10-15") }
})Here’s something that would be painful in SQL: you can query for fields that might not exist in all documents:
// Find all reviews with videos
db.customer_reviews.find({ video_url: { $exists: true } })
// Find reviews with sentiment analysis
db.customer_reviews.find({ sentiment_score: { $exists: true } })These queries don’t fail when they encounter documents without these fields. Instead, they simply return the documents that match.
A quick note on performance
As your collection grows beyond a few thousand documents, you’ll want to create indexes on fields you query frequently. Think of indexes like the index in a book — instead of flipping through every page to find “MongoDB,” you can jump straight to the right section.
Let’s create an index on product_id since we’ve been querying it:
db.customer_reviews.createIndex({ product_id: 1 })The 1 means ascending order (you can use -1 for descending). MongoDB will now keep a sorted reference to all product_id values, making our product queries lightning fast even with millions of reviews. You don’t need to change your queries at all; MongoDB automatically uses the index when it helps.
Update existing documents
Updating documents using updateOne is equally flexible. Let’s say the customer service team starts adding sentiment scores to reviews:
db.customer_reviews.updateOne(
{ customer_id: "cust_12345" },
{
$set: {
sentiment_score: 0.72,
sentiment_label: "positive"
}
}
)We used the $set operator, which tells MongoDB which fields to add or modify. In the output MongoDB tells us exactly what happened:
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}We just added new fields to one document. The others? Completely untouched, with no migration required.
When someone finds a review helpful, we can increment the vote count using $inc:
db.customer_reviews.updateOne(
{ customer_id: "cust_67890" },
{ $inc: { helpful_votes: 1 } }
)This operation is atomic, meaning it’s safe even with multiple users voting simultaneously.
Analytics Without Leaving MongoDB
MongoDB’s aggregate method lets you run analytics directly on your operational data using what’s called an aggregation pipeline, which is a series of data transformations.
Average rating and review count
Let’s answer a real business question: What’s the average rating and review count for each product?
db.customer_reviews.aggregate([
{
$group: {
_id: "$product_id",
avg_rating: { $avg: "$rating" },
review_count: { $sum: 1 },
total_helpful_votes: { $sum: "$helpful_votes" }
}
},
{
$sort: { avg_rating: -1 }
}
]){
_id: 'wireless_headphones_pro',
avg_rating: 4.666666666666667,
review_count: 3,
total_helpful_votes: 81
}
{
_id: 'laptop_stand_adjustable',
avg_rating: 4,
review_count: 2,
total_helpful_votes: 13
}Here’s how the pipeline works: first, we group ($group) by product_id and calculate metrics for each group using operators like $avg and $sum. Then we sort ($sort) by average rating, using -1 to sort in descending order. The result gives us exactly what product managers need to understand product performance.
Trends over time
Let’s try something more complex by analyzing review trends over time:
db.customer_reviews.aggregate([
{
$group: {
_id: {
month: { $month: "$review_date" },
year: { $year: "$review_date" }
},
review_count: { $sum: 1 },
avg_rating: { $avg: "$rating" },
verified_percentage: {
$avg: { $cond: ["$verified_purchase", 1, 0] }
}
}
},
{
$sort: { "_id.year": 1, "_id.month": 1 }
}
]){
_id: {
month: 10,
year: 2024
},
review_count: 5,
avg_rating: 4.4,
verified_percentage: 0.8
}This query groups reviews by month using MongoDB’s date operators like $month and $year, calculates the average rating, and computes what percentage were verified purchases. We used $cond to convert true/false values to 1/0, then averaged them to get the verification percentage. Marketing can use this to track review quality over time.
These queries answer real business questions directly on your operational data. Now let’s see how to integrate this with Python for complete data pipelines.
Connecting MongoDB to Your Data Pipeline
Real data engineering connects systems. MongoDB rarely works in isolation because it’s part of a larger data ecosystem. Let’s connect it to Python, where you can integrate it with the rest of your pipeline.
Exporting data from MongoDB
You can export data from Compass in a few ways: export entire collections from the Documents tab, or build aggregation pipelines in the Aggregation tab and export those results. Choose JSON or CSV depending on your downstream needs.
For more flexibility with specific queries, let’s use Python. First, install PyMongo, the official MongoDB driver:
pip install pymongo pandasHere’s a practical example that extracts data from MongoDB for analysis:
from pymongo import MongoClient
import pandas as pd
# Connect to MongoDB Atlas
# In production, store this as an environment variable for security
connection_string = "mongodb+srv://username:[email protected]/"
client = MongoClient(connection_string)
db = client.ecommerce_analytics
# Query high-rated reviews
high_rated_reviews = list(
db.customer_reviews.find({
"rating": {"$gte": 4}
})
)
# Convert to DataFrame for analysis
df = pd.DataFrame(high_rated_reviews)
# Clean up MongoDB's internal _id field
if '_id' in df.columns:
df = df.drop('_id', axis=1)
# Handle optional fields gracefully (remember our schema flexibility?)
df['has_photo'] = df['photo_url'].notna()
df['has_video'] = df['video_url'].notna()
# Analyze product performance
product_metrics = df.groupby('product_id').agg({
'rating': 'mean',
'helpful_votes': 'sum',
'customer_id': 'count'
}).rename(columns={'customer_id': 'review_count'})
print("Product Performance (Last 30 Days):")
print(product_metrics)
# Export for downstream processing
df.to_csv('recent_positive_reviews.csv', index=False)
print(f"\nExported {len(df)} reviews for downstream processing")
This is a common pattern in data engineering: MongoDB stores operational data, Python extracts and transforms it, and the results feed into SQL databases, data warehouses, or BI tools.
Where MongoDB fits in larger data architectures
This pattern, using different databases for different purposes, is called polyglot persistence. Here’s how it typically works in production:
- MongoDB handles operational workloads: Flexible schemas, high write volumes, real-time applications
- SQL databases handle analytical workloads: Complex queries, reporting, business intelligence
- Python bridges the gap: Extracting, transforming, and loading data between systems
You might use MongoDB to capture raw user events in real-time, then periodically extract and transform that data into a PostgreSQL data warehouse where business analysts can run complex reports. Each database does what it does best.
The key is understanding that modern data pipelines aren’t about choosing MongoDB OR SQL… they’re about using both strategically. MongoDB excels at evolving schemas and horizontal scaling. SQL databases excel at complex analytics and mature tooling. Real data engineering combines them thoughtfully.
Review and Next Steps
You’ve covered significant ground today. You can now set up MongoDB, handle schema changes without migrations, write queries and aggregation pipelines, and connect everything to Python for broader data workflows.
This isn’t just theoretical knowledge. You’ve worked through the same challenges that come up in real projects: evolving data structures, flexible document storage, and integrating NoSQL with analytical tools.
Your next steps depend on what you’re trying to build:
If you want deeper MongoDB knowledge:
- Learn about indexing strategies for query optimization
- Explore change streams for real-time data processing
- Try MongoDB’s time-series collections for IoT data
- Understand sharding for horizontal scaling
- Practice thoughtful document design (flexibility doesn’t mean “dump everything in one document”)
- Learn MongoDB’s consistency trade-offs (it’s not just “SQL but schemaless”)
If you want to explore the broader NoSQL ecosystem:
- Try Redis for caching. It’s simpler than MongoDB and solves different problems
- Experiment with Elasticsearch for full-text search across your reviews
- Look at Cassandra for true time-series data at massive scale
- Consider Neo4j if you need to analyze relationships between customers
If you want to build production systems:
- Create a complete ETL pipeline: MongoDB → Airflow → PostgreSQL
- Set up monitoring with MongoDB Atlas metrics
- Implement proper error handling and retry logic
- Learn about consistency levels and their trade-offs
The concepts you’ve learned apply beyond MongoDB. Document flexibility appears in DynamoDB and CouchDB. Aggregation pipelines exist in Elasticsearch. Using different databases for different parts of your pipeline is standard practice in modern systems.
You now understand when to choose NoSQL versus SQL, matching tools to problems. MongoDB handles flexible schemas and horizontal scaling well, whereas SQL databases excel at complex queries and transactions. Most real systems use both.
The next time you encounter rapidly changing requirements or need to scale beyond a single server, you’ll recognize these as problems that NoSQL databases were designed to solve.
Source link

You may also like

How Much Does It Cost To Build An Online Tutoring Website?

Thought Leader Q&A: Exploring ADDIE With Dr. Jill Stefaniak
